Handling Cookies is a Minefield
HTTP cookies are a small piece of data set by either Javascript or HTTP servers, and which are essential for maintaining state on the otherwise stateless system known as the World Wide Web. Once set, web browsers will continue to forward them along for every properly scoped HTTP request until they expire.
I had been more than content to ignore the vagaries of how cookies function until the end of time, except that one day I stumbled across this innocuous piece of Javascript:
const favoriteCookies = JSON.stringify({
ginger: "snap",
peanutButter: "chocolate chip",
snicker: "doodle",
});
document.cookie = ` cookieNames=${favoriteCookies}` ;
This code functioned completely fine, as far as browsers were concerned. It took a piece of boring (but tasty) JSON and saved the value into a session cookie. While this was slightly unusual — most code will serialize JSON to base64 prior to setting them as a cookie, there was nothing here that browsers had any issue with. They happily allowed the cookie to be set and sent along to the backend web server in the HTTP header:
GET / HTTP/1.1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.9
Connection: keep-alive
Cookie: cookieNames={"ginger":"snap","peanutButter":"chocolate chip","snicker":"doodle"}
Host: example.com
Which was all well and good, until it got passed along to some code that used the Go standard library. The Go standard library couldn't parse the cookie, leading to cascading failures all the way up the stack. So what happened?
The Specification
Cookies were initially defined in RFC 2109 (1997), and subsequently updated in RFC 2965 (2000) and RFC 6265 (2011), with a draft version that is in the process of being updated (and is what this article uses).
There are two sections of the RFC that pertain to cookie values:
Section 4.1.1 (on how servers should send cookies)
Informally, the Set-Cookie response header field contains a cookie,
which begins with a name-value-pair, followed by zero or more
attribute-value pairs. Servers SHOULD NOT send Set-Cookie header
fields that fail to conform to the following grammar:
set-cookie = set-cookie-string
set-cookie-string = BWS cookie-pair *( BWS ";" OWS cookie-av )
cookie-pair = cookie-name BWS "=" BWS cookie-value
cookie-name = 1*cookie-octet
cookie-value = *cookie-octet / ( DQUOTE *cookie-octet DQUOTE )
cookie-octet = %x21 / %x23-2B / %x2D-3A / %x3C-5B / %x5D-7E
; US-ASCII characters excluding CTLs,
; whitespace DQUOTE, comma, semicolon,
; and backslash
Section 5.6 (on how browsers should accept cookies)
A user agent MUST use an algorithm equivalent to the following algorithm
to parse a set-cookie-string:
1. If the set-cookie-string contains a %x00-08 / %x0A-1F / %x7F character
(CTL characters excluding HTAB):
Abort these steps and ignore the set-cookie-string entirely.
2. If the set-cookie-string contains a %x3B (";") character:
The name-value-pair string consists of the characters up to, but not
including, the first %x3B (";"), and the unparsed-attributes consist
of the remainder of the set-cookie-string (including the %x3B (";")
in question).
Otherwise:
1. The name-value-pair string consists of all the characters contained in
the set-cookie-string, and the unparsed-attributes is the empty string.
There are three things that should immediately jump out to you:
- What servers SHOULD send and what browsers MUST accept are not aligned, a classic example of the tragedy of following Postel's Law.
- There is nothing here that limits what cookie values are acceptable for browsers to send to servers, aside from the semicolon delimiter. This might be fine if servers only received cookies they themselves had set, but cookies can also come from
document.cookieand contain values outside the%x21,%x23-2B,%x2D-3A,%x3C-5B, and%x5D-7Echaracters as allowed bySet-Cookie. - It doesn't acknowledge how standard libraries that handle
Cookieheaders should behave: should they act like user agents or like servers? Should they be permissive or proscriptive? Should they behave differently in different contexts?
And herein lies the very crux of the resulting issue I ran into: everything behaves differently, and it's a miracle that cookies work at all.
Web Browsers
First, let's start with how web browsers behave. The teams behind Gecko (Firefox), Chromium, and WebKit (Safari) work together constantly, so it would be reasonable to expect them to all behave the same… right?
Before we dig in, remember that the RFC contradictorily says that Set-Cookie headers may contain any ASCII character besides control characters, double quotes, commas, semicolons, and backslashes, but that browsers should accept any cookie value that does not contain control characters.
Firefox
Firefox's code for valid cookie values looks like this:
bool CookieCommons::CheckValue(const CookieStruct& aCookieData) {
// reject cookie if value contains an RFC 6265 disallowed character - see
// https://bugzilla.mozilla.org/show_bug.cgi?id=1191423
// NOTE: this is not the full set of characters disallowed by 6265 - notably
// 0x09, 0x20, 0x22, 0x2C, and 0x5C are missing from this list.
const char illegalCharacters[] = {
0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x0A, 0x0B, 0x0C,
0x0D, 0x0E, 0x0F, 0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17,
0x18, 0x19, 0x1A, 0x1B, 0x1C, 0x1D, 0x1E, 0x1F, 0x3B, 0x7F, 0x00};
const auto* start = aCookieData.value().BeginReading();
const auto* end = aCookieData.value().EndReading();
auto charFilter = [&](unsigned char c) {
if (StaticPrefs::network_cookie_blockUnicode() && c >= 0x80) {
return true;
}
return std::find(std::begin(illegalCharacters), std::end(illegalCharacters),
c) != std::end(illegalCharacters);
};
return std::find_if(start, end, charFilter) == end;
}
0x7F was fixed in bug 1797235 (Firefox 108)Firefox accepts five characters which RFC recommends that servers not send:
0x09(horizontal tab)0x20(spaces)0x22(double quotes)0x2C(commas)0x5C(backslashes)
This was initially done to provide parity with Chrome in some long-ago era and lingers on in both codebases.
Astute observers might note that Firefox has a network.cookie.blockUnicode setting that this code checks against, and which rejects all values above 0x80. That groundwork was laid as a result of this research and can be tracked in bug 1797231.
Chromium
The Chromium code for valid cookie values looks like so:
bool ParsedCookie::IsValidCookieValue(const std::string& value) {
// IsValidCookieValue() returns whether a string matches the following
// grammar:
//
// cookie-value = *cookie-value-octet
// cookie-value-octet = %x20-3A / %x3C-7E / %x80-FF
// ; octets excluding CTLs and ";"
//
// This can be used to determine whether cookie values contain any invalid
// characters.
//
// Note that RFC6265bis section 4.1.1 suggests a stricter grammar for
// parsing cookie values, but we choose to allow a wider range of characters
// than what's allowed by that grammar (while still conforming to the
// requirements of the parsing algorithm defined in section 5.2).
//
// For reference, see:
// - https://crbug.com/238041
for (char i : value) {
if (HttpUtil::IsControlChar(i) || i == ';')
return false;
}
return true;
}
// Whether the character is a control character (CTL) as defined in RFC 5234
// Appendix B.1.
static inline bool IsControlChar(char c) {
return (c >= 0x00 && c <= 0x1F) || c == 0x7F;
}
Chrome is slightly more restrictive than Firefox, refusing to accept the 0x09 (horizontal tab) in its cookie values.
Nevertheless (and contrary to the RFC), it is perfectly happy to receive and send spaces, double quotes, commas, backslashes, and unicode characters.
Safari (WebKit)
I'm not able to get access to the code for cookie storage, as it is buried inside the closed source CFNetwork. That said, we can nevertheless examine its internals by running this piece of Javascript:
for (i=0; i<256; i++) {
let paddedIndex = i.toString().padStart(3, '0') +
'_' + '0x' + i.toString(16).padStart(2, '0');
// set a cookie with name of "cookie" + decimal char + hex char
// and a value of the character surrounded by a space and two dashes
document.cookie=` cookie${paddedIndex}=-- ${String.fromCharCode(i)} --` ;
}
document.cookie='cookieUnicode=🍪';
:::text
cookie007_0x07 -- localhost / Session 16 B
cookie008_0x08 -- localhost / Session 16 B
cookie009_0x09 -- -- localhost / Session 21 B
cookie010_0x0a -- localhost / Session 16 B
cookie011_0x0b -- localhost / Session 16 B
(snip for brevity)
cookie030_0x1e -- localhost / Session 16 B
cookie031_0x1f -- localhost / Session 16 B
cookie032_0x20 -- -- localhost / Session 21 B
cookie033_0x21 -- ! -- localhost / Session 21 B
cookie034_0x22 -- " -- localhost / Session 21 B
cookie035_0x23 -- # -- localhost / Session 21 B
(snip for brevity)
cookie042_0x2a -- * -- localhost / Session 21 B
cookie043_0x2b -- + -- localhost / Session 21 B
cookie044_0x2c --,-- localhost / Session 19 B
(snip for brevity)
cookie044_0x5c -- \ -- localhost / Session 19 B
As Safari stops processing a cookie once it sees a disallowed character, it's easy to see that 0x09 (horizontal tab), 0x20 (space), 0x22 (double quote), and 0x5C (backslash) are okay, but 0x7F (delete), 0x80-FF (high ASCII / Unicode) characters are disallowed.
Unlike Firefox and Chrome which follow the instructions in the RFC to “abort these steps and ignore the cookie entirely” when encountering a cookie with a control character, Safari does not ignore the cookie but instead accepts the cookie value for everything up until that character.
Oddly enough, this quest has uncovered a bizarre Safari bug — setting a cookie with a value of -- , -- seems to result in it trimming the whitespace around the comma.
Standard Libraries
Golang
Let's start with Golang's cookie code, which is where I ran into the problem in the first place.
// sanitizeCookieValue produces a suitable cookie-value from v.
// https://tools.ietf.org/html/rfc6265#section-4.1.1
//
// We loosen this as spaces and commas are common in cookie values
// but we produce a quoted cookie-value if and only if v contains
// commas or spaces.
// See https://golang.org/issue/7243 for the discussion.
func sanitizeCookieValue(v string) string {
v = sanitizeOrWarn("Cookie.Value", validCookieValueByte, v)
if len(v) == 0 {
return v
}
if strings.ContainsAny(v, " ,") {
return `"` + v + `"`
}
return v
}
func validCookieValueByte(b byte) bool {
return 0x20 <= b && b < 0x7f && b != '"' && b != ';' && b != '\\'
}
Golang falls relatively close to the RFC's wording on how servers should behave with Set-Cookie, only differing by allowing 0x20 (space) and 0x2C (comma) due to them commonly occurring in the wild.
You can already see the struggles that programming languages have to deal with — they have to both receive values from browsers in line with Section 5, but also send cookies as per Section 4.1.1.
This can have pretty serious consequences, as you can see from running this code:
package main
import (
"fmt"
"net/http"
)
func main() {
rawCookies :=
` cookie1=foo; ` +
` cookie2={"ginger":"snap","peanutButter":"chocolate chip","snicker":"doodle"}; ` +
` cookie3=bar`
header := http.Header{}
header.Add("Cookie", rawCookies)
request := http.Request{Header: header}
fmt.Println(request.Cookies())
}
Which outputs only:
[cookie1=foo cookie3=bar]
Invisibly dropping a cookie that all major browsers accept, without any sort of exception to the effect that this is happening. Still, dropping a cookie it didn't understand without any other side effects isn't as bad as it could be.
PHP
Many languages, such as PHP, don't have native functions for parsing cookies, which makes it somewhat difficult to definitively say what it allows and does not allow.
That said, we can set cookies using the code below and see how PHP responds:
[0x09, 0x0D, 0x10, 0x20, 0x22, 0x2C, 0x5C, 0x7F, 0xFF].forEach(i => {
let paddedIndex = i.toString().padStart(3, '0') + '_' +
'0x' + i.toString(16).padStart(2, '0');
document.cookie=` cookie${paddedIndex}=-- ${String.fromCharCode(i)} --` ;
});
document.cookie='cookieUnicode=🍪';
Output:
cookie009_0x09: -- --
cookie009_0x10: -- --
cookie009_0x0d: -- --
cookie032_0x20: -- --
cookie034_0x22: -- " --
cookie044_0x2c: -- , --
cookie092_0x5c: -- \ --
cookie255_0x7f: -- --
cookie255_0xff: -- ÿ --
cookieUnicode: 🍪
When it comes to control characters, PHP's behavior is all over the place. 0x00-0x09 all work fine, as do things like 0x0D (carriage return), but if you use 0x10 (data link escape) or 0x7F (delete), PHP will completely error out with a 400 Bad Request error.
Python
import http.cookies
raw_cookies = (
'cookie1=foo; '
'cookie2={"ginger":"snap","peanutButter":"chocolate chip","snicker":"doodle"}; '
'cookie3=bar'
)
c = http.cookies.SimpleCookie()
c.load(raw_cookies)
print(c)
Output:
>>> Set-Cookie: cookie1=foo
Python invisibly aborts the loading of additional cookies inside SimpleCookie.load() as soon as it encounters one it doesn't understand. This can be very dangerous when you consider that a subdomain could feasibly set a cookie on the base domain which would completely break all cookies for all domains of a given site.
It's even messier when it comes to control characters:
import http.cookies
for i in range(0, 32):
raw_cookie = f"cookie{hex(i)}={chr(i)}"
c = http.cookies.SimpleCookie()
c.load(raw_cookie)
for name, morsel in c.items():
print(f"{name}: value: {repr(morsel.value)}, length: {len(morsel.value)}")
Output:
>>> cookie0x9: value: '', length: 0
>>> cookie0xa: value: '', length: 0
>>> cookie0xb: value: '', length: 0
>>> cookie0xc: value: '', length: 0
>>> cookie0xd: value: '', length: 0
Here we can see that Python invisibly drops a lot of cookies with control characters, and loads others improperly. Note that if you guard those values with something like:
raw_cookie = f"cookie{hex(i)}=aa{chr(i)}aa"
Then none of the control character cookies will load. Overall, Python is extremely inconsistent and unpredictable in its behavior when it comes to loading cookies.
Ruby
require "cgi"
raw_cookie = 'ginger=snap; ' +
"cookie=chocolate \x13 \t \" , \\ \x7f 🍪 chip; " +
'snicker=doodle'
cookies = CGI::Cookie.parse(raw_cookie)
puts cookies
puts cookies["cookie"].value()
puts cookies["cookie"].value().to_s()
Output:
{"ginger"=>#<CGI::Cookie: "ginger=snap; path=">, "cookie"=>#<CGI::Cookie: "cookie=chocolate+%13+%09+%22+%2C+%5C+%7F+%F0%9F%8D%AA+chip; path=">, "snicker"=>#<CGI::Cookie: "snicker=doodle; path=">}
chocolate " , \ 🍪 chip
cookie=chocolate+%13+%09+%22+%2C+%5C+%7F+%F0%9F%8D%AA+chip; path=
The Ruby library appears pretty permissive, seeming to accept every character during parsing and then percent-encoding it when being pulled from the cookie jar.
This may well be the optimal behavior (if such a thing can be said to exist with cookies), but I can certainly see cases where code setting a cookie via document.cookie would not expect to see it reflected back in percent-encoded form.
Rust
use cookie::Cookie;
fn main() {
let c = Cookie::parse("cookie=chocolate , \" \t foo \x13 ñ 🍪 chip;").unwrap();
println!("{:?}", c.name_value());
}
Output:
("cookie", "chocolate , \" \t foo \u{13} ñ 🍪 chip")
Rust doesn't ship any cookie handling facilities by default, so this is looking at the popular cookie crate. As configured by default, it appears to be the most permissive of the programming languages, accepting any UTF-8 string tossed at it.
The World Wide Web, aka Why This Matters
The wildly differing behavior between browsers and languages certainly makes for some riveting tables, but how does all this play out in the real world?
When I first discovered this in the real world, it was only through sheer luck that it wasn't a catastrophe. A manual tester was playing around with a third-party library update and had run into a strange set of errors on our testing site. Without bringing it to my attention, this update — doing something unlikely to be caught in automated testing — would have certainly been pushed to production. As a result, every future website visitor would have received a broken cookie and been locked out with an inscrutable error until the update was reverted and the cookies were cleared out.
And that's exactly the problem with this specification ambiguity — it's such an easy mistake to make that millions of websites and companies are only an intern away from a complete meltdown. And it doesn't only affect tiny websites on obscure frameworks, as major websites such as Facebook, Netflix, WhatsApp, and Apple are affected.
You can see for yourself how easy of a mistake this is to make by pasting this simple code fragment into your browser console, substituting .grayduck.mn for the domain you're testing, e.g. .facebook.com:
document.cookie="unicodeCookie=🍪; domain=.grayduck.mn; Path=/; SameSite=Lax"
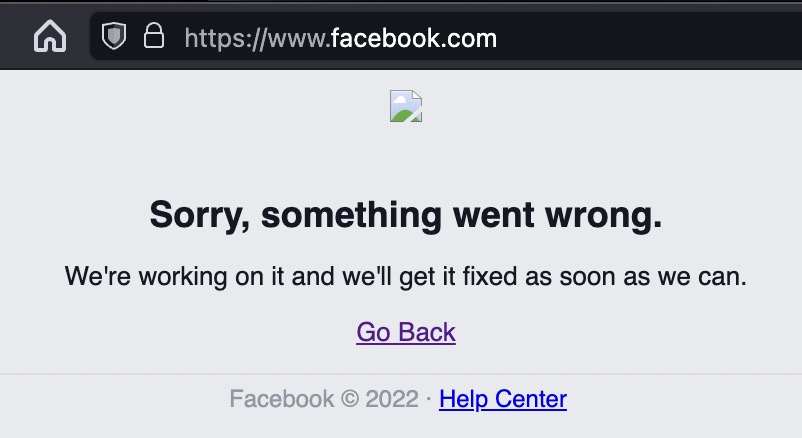
Instagram & Threads
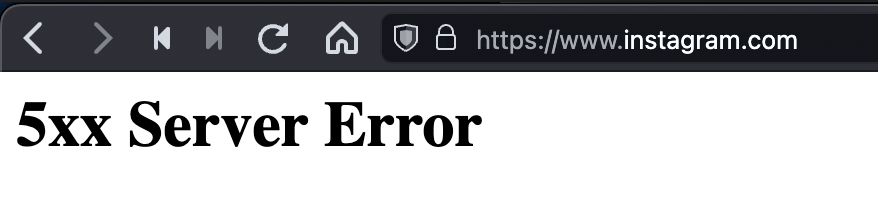
Netflix
Okta
Amazon
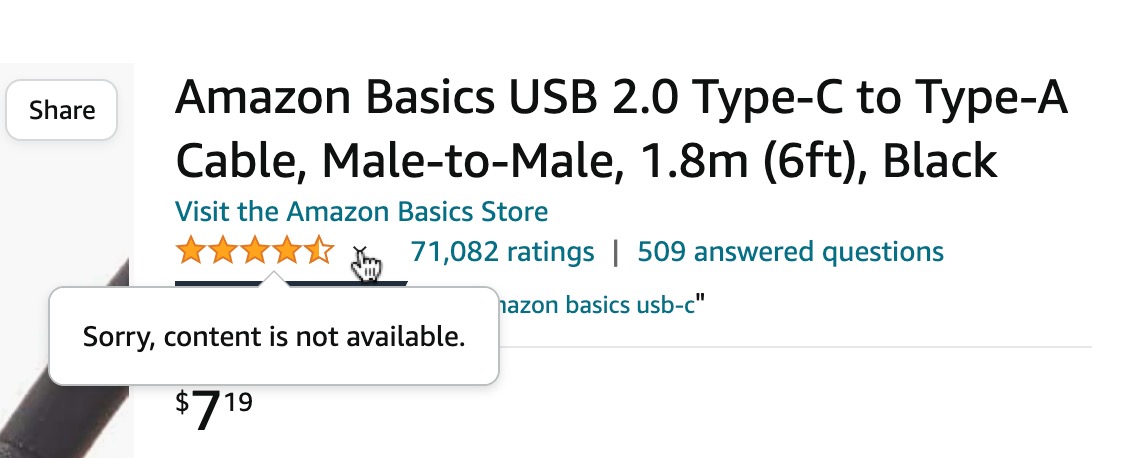
Amazon Web Services
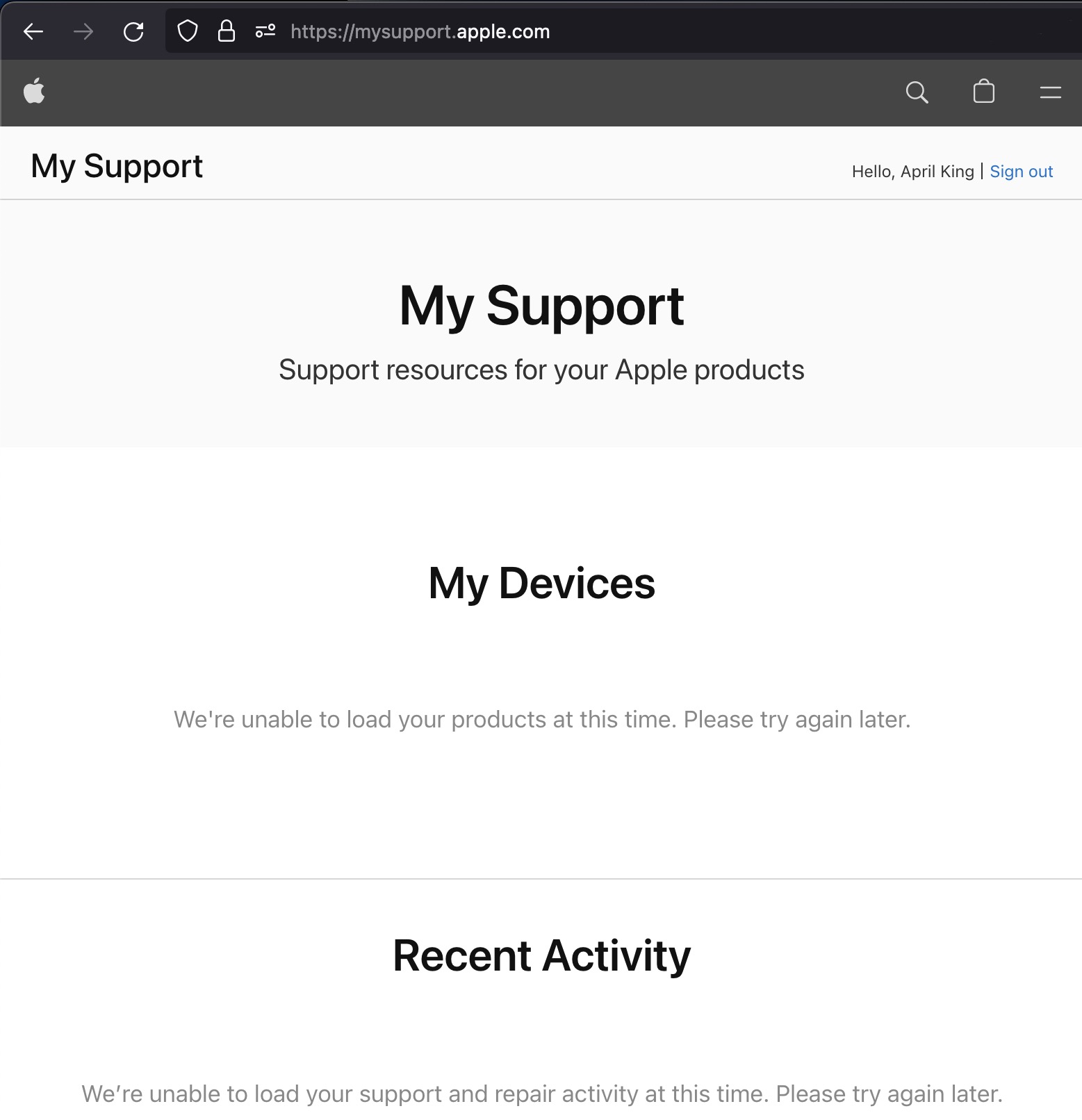
Apple Support
Best Buy
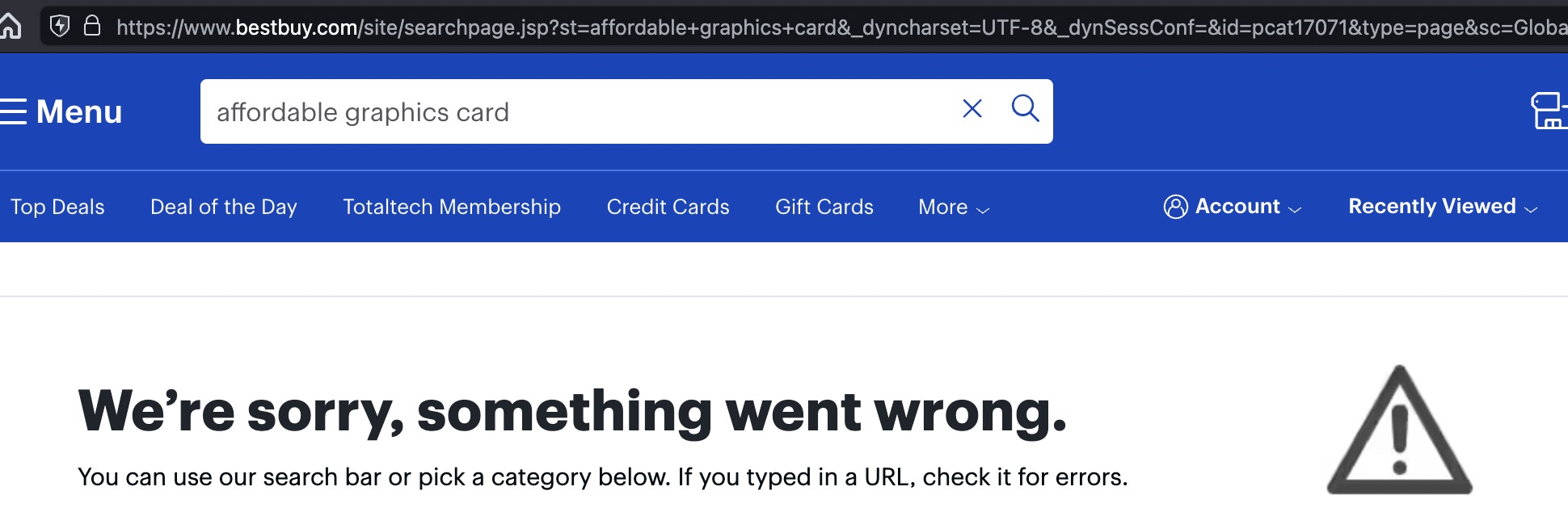
eBay
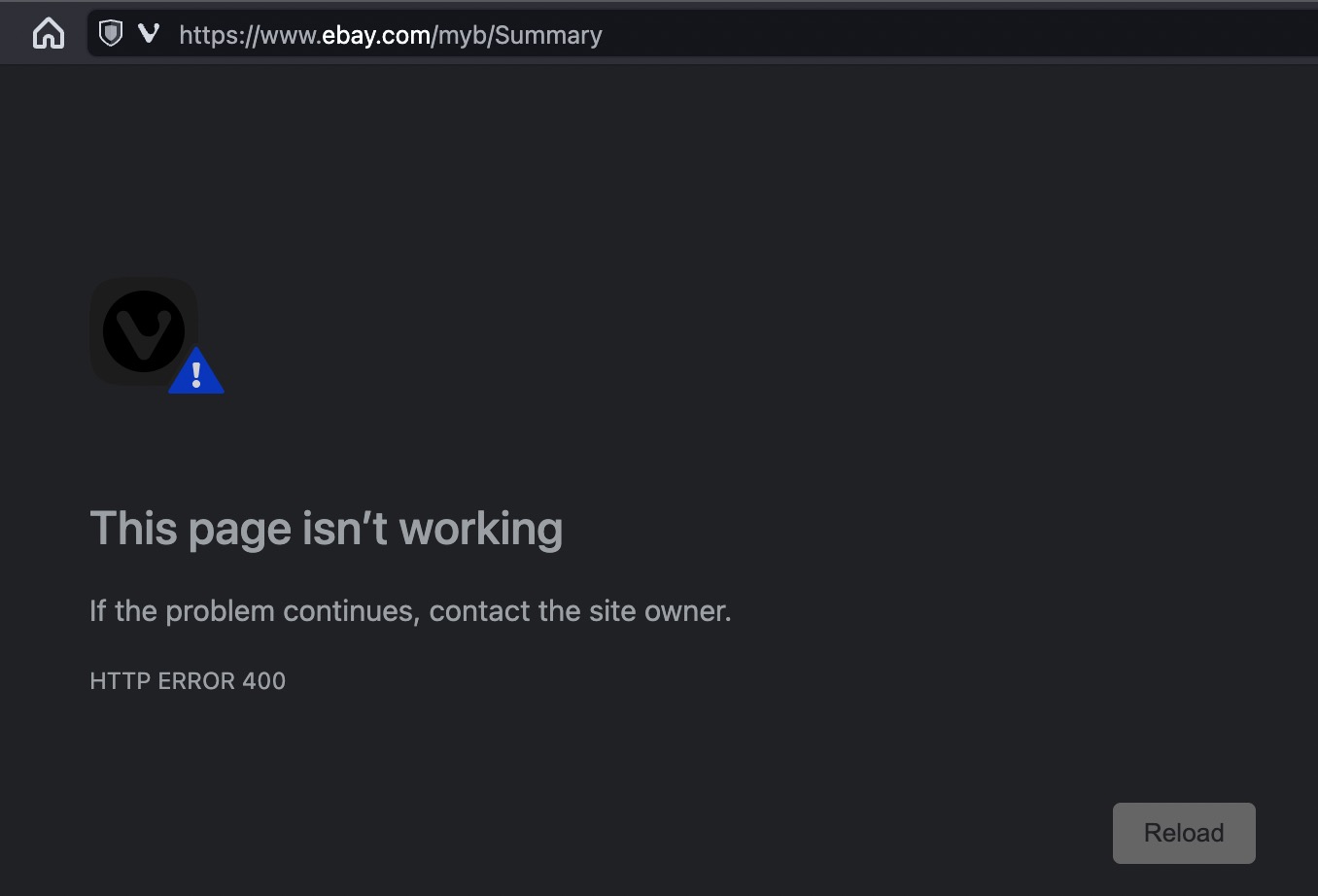
Home Depot
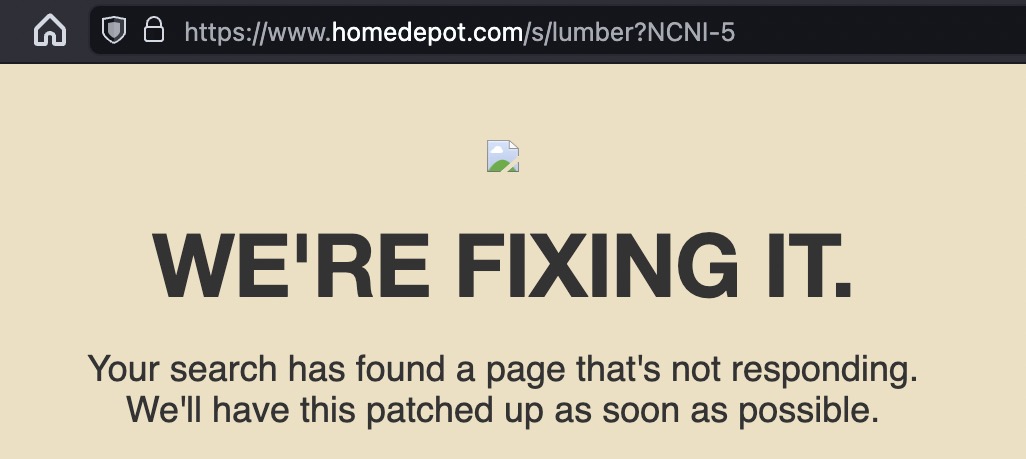
Intuit
Outlook
How do we fix this?
It's probably not much of a surprise that fixing problems in 30-year-old foundational specifications is really, really hard. And for this problem, it's unlikely that there is a good fix.
Blocking these cookies on the browser side was considered and worked on by both Mozilla and Google:
- Mozilla: bug 1797235 aka CVE-2023-5723, and bug 1797231
- Google: bug 40061459
But it turns out unilateral blocking is quite complicated because while non-ASCII cookies aren't super common overall, affecting only a bit under 0.01% of all cookies, telemetry has found they are considerably more common in countries like Argentina, Mexico, and Finland. While Mozilla did implement a preference that could be toggled quickly (network.cookie.blockUnicode), it hasn't been enabled due to behavioral compatibility issues with Chromium.
Fixing it on the server-side is potentially feasible, but it affects millions of websites and most of the errors caused by this problem are buried deep in programming languages and web frameworks. It might be possible for places like Facebook and Netflix to mitigate the issue, but the average website operator is not going to have the time or ability to resolve the issue.
In truth, the true fix for this issue almost certainly lies in the IETF HTTP Working Group updating the cookie specification to both align with itself and to be strict on how systems handling cookies should behave. Whether non-ASCII characters should be allowed should be identical regardless of whether server-side or on user agents.
And regardless, the steps around how browsers, programming languages, and frameworks should handle cookie processing need to be explicit, in much the way that modern W3C standards such as Content Security Policy do. Aborting the processing of other cookies because one cookie is malformed is unacceptable when such behavior can lead to a wide variety of unexpected behavior.
These processing steps should probably look like something like:
• Start with field-value
• Split on ; and ,, giving list of "raw-cookie-pair". Comma is NOT treated a synonym for semicolon in order to support combining headers, despite RFC7230 section 3.2.2.
For each raw-cookie-pair:
◦ If the pair does not contain =, then skip to next raw-cookie-pair
◦ Remove leading and trailing whitespace
◦ Treat portion before first = as cookie-name-octets
◦ Treat portion after first = as cookie-value-octets
◦ If cookie-value-octets starts with DQUOTE, then:
‣ Remove one DQUOTE at start
‣ Remove one DQUOTE at end, if present
◦ If resulting cookie-name-octets, cookie-value-octets, or both are unacceptable to server, then skip to next raw-cookie-pair
◦ Process resulting [cookie-name-octets, cookie-value-octets] tuple in server defined manner
Servers SHOULD further process cookie-name-octets and reject any tuple where the cookie-name-octets are not a token. Servers SHOULD further process and cookie-value-octets and reject any tuple where cookie-value-octets contains octets not in cookie-octet.
Summary Table
| CTLs1 | htab | space | dquote | comma | backslash | delete | 0x80-FF (and Unicode) |
|
|---|---|---|---|---|---|---|---|---|
| RFC 6235 (Section 4.1.1) | No | No | No | No | No | No | No | No | RFC 6265 (Section 5.6) | No | Yes | Yes | Yes | Yes | Yes | No | ?? |
| Firefox | No2 | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Chromium | No | No | Yes | Yes | Yes | Yes | No | Yes | Safari | No3 | Yes | Yes | Yes | Yes4 | Yes | No | No |
| Golang | ?? | No | Yes | No | Yes | No | No | No | Python | Yes5 | No | No | No | Yes | No | No | No |
| Ruby (CGI) | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Rust | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
- not as defined as in RFC 5234, but instead as
\x00-08and\x0A-x1F(e.g. CTLs minus htab and delete) - Mozilla stopped allowing CTLs in
document.cookieas of Firefox 108 - does not abort processing and ignore the cookie as the RFC requires
- seems to remove whitespace around commas in some conditions
- sometimes allows
0x0A-0Dbut fails to store them in the cookie value, aborts at other times
Thanks
I couldn't have written this article without a bunch of help along the way. I'd like to thank:
- Po-Ning Tseng, for helping me investigate this issue in the first place
- Dan Veditz at Mozilla, for his inexhaustible knowledge and endless kindness
- Frederik Braun, for his helpful early feedback
- Steven Bingler at Google, for pushing on getting this issue fixed
- Peter Bowen, for his thoughts on how cookie processing probably should happen
- Chris Palmer and David Schinazi, for their insightful proofreading
- Stefan Bühler, who stumbled across some of this stuff over a decade ago
- kibwen on HackerNews, for pointing out the Rust crate situation